2022年1月25日整理发布:随着游戏世界变得越来越庞大和复杂,确保它们可玩且没有错误对于开发人员来说变得越来越困难。游戏公司正在寻找包括人工智能在内的新工具,以帮助克服测试其产品的日益严峻的挑战。
Electronic Arts 的一组 AI 研究人员发表的一篇新论文表明,深度强化学习代理可以帮助测试游戏并确保它们是平衡的和可解决的。
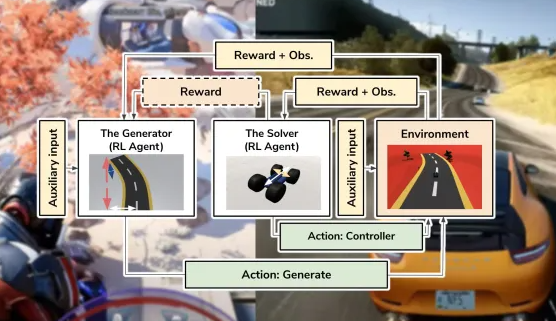
EA 研究人员提出的“用于程序内容生成的对抗性强化学习”是一种新颖的方法,它解决了以前用于测试游戏的 AI 方法的一些缺点。
测试大型游戏环境
EA 高级机器学习研究工程师、该论文的主要作者 Linus Gisslén 告诉TechTalks: “今天的大游戏可以拥有 1000 多名开发人员,并且经常在 PlayStation、Xbox、移动设备等平台上发布跨平台。” “此外,随着开放世界游戏和现场服务的最新趋势,我们看到许多内容必须以我们以前在游戏中从未见过的规模通过程序生成。所有这一切都引入了很多‘移动部件’,它们都可能在我们的游戏中产生错误。”
开发人员目前有两个主要工具可以用来测试他们的游戏:脚本机器人和人类游戏测试器。人类游戏测试人员非常擅长发现错误。但是在处理广阔的环境时,它们的速度可能会大大减慢。他们也会感到无聊和分心,尤其是在一个非常大的游戏世界中。另一方面,脚本机器人是快速且可扩展的。但它们无法与人类测试人员的复杂性相匹敌,而且它们在开放世界游戏等大型环境中表现不佳,在这种环境中,盲目的探索不一定是成功的策略。
“我们的目标是使用强化学习 (RL) 作为一种方法,将人类的优势(自学习、自适应和好奇)与脚本机器人(快速、廉价和可扩展)相结合,”Gisslén 说。
强化学习是机器学习的一个分支,其中 AI 代理尝试采取行动以最大化其在其环境中的奖励。例如,在游戏中,RL 代理首先采取随机动作。基于它从环境中获得的奖励或惩罚(活着、失去生命或健康、获得积分、完成一个关卡等),它制定了一个能够产生最佳结果的行动策略。